Explainable AI - Methods II
Visual Explainability Methods
-
Saliency Maps: visually show which features are most important in a particular prediction. They can be generated for 1D, 2D and ND inputs. For example, here is for radiology:
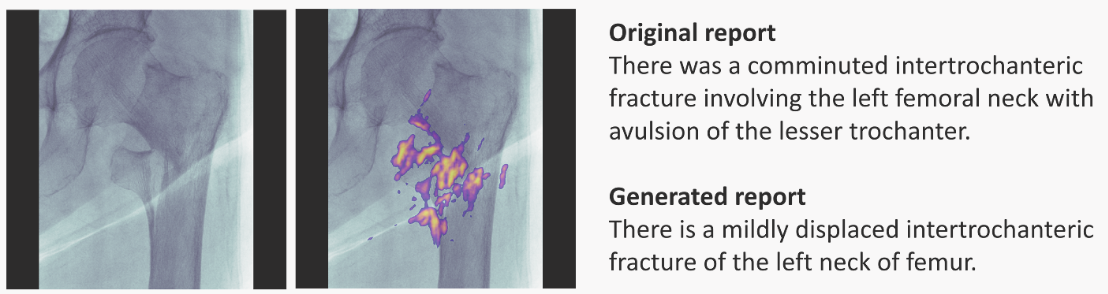
Left-most: input image; next: input + saliency map; right-most: doctor's annotation (top) and RNN-model generated annotation (bottom). Image taken from paper.
-
Variations: Individual Conditional Expectation, Partial Dependency Plots, can all help as well.
- ICE:
(...) operates on instance level, depicting the model’s decision boundary as a function of a single feature, with the rest of them staying fixed
. PDPs are a similar idea, but the remaining features are average values over the dataset points, rather than particular values of an instance.
- ICE:
-
Validity Interval Analysis: another technique fitting the NN behaviour to try to extract explanations.
Feature Relevance
- SHAP (possibly also LIME),
- Influence Functions.
Simplification
- LIME (possibly also SHAP). Explained in previous post,
- Anchors: the authors of LIME also proposed this method, described by Principles and practice of explainability in ML:
A similar technique, called anchors, can be found in (Ribeiro et al., 2018). Here the objective is again to approximate a model locally, but this time not by using a linear model. Instead, easy to understand "if-then" rules that anchor the model's decision are employed. The rules aim at capturing the essential features, omitting the rest, so it results in more sparse explanations.
Other methods
- Dimensionality Reduction: Principal Component Analysis, t-SNE, Dimensionality Reduction, Independent Component Analysis, Non-negative Matrix Factorisation.
- Counterfactuals: The same paper as above describes:
There has been considerable recent development in the socalled counterfactual explanations (Wachter et al., 2018). Here, the objective is to create instances as close as possible to the instance we wish to explain, but such that the model classifies the new instance in a different category.
Explanation-producing Architectures
Architectures designed to make explaining part of their operation easier.
-
Using Explicit Attention: An attention layer/mask learns how parts of an input embedding pay attention to other parts. The layer is somewhat interpretable. In chemistry, it could learn which atoms connect (or pay attention to) other atoms.
-
Dissentangled Representations:
Disentangled representations have individual dimensions that describe meaningful and independent factors of variation.
—Explaining Explainability (2018). Examples of architectures are -VAE, INFOGan, capsule networks.