Atoms Vectors - SkipAtom
Atom2Vec was already described; now it's time for SkipAtom, another algorithm to learn atom embeddings.
Method
First, compounds are downloaded. Then, the Voronoi Decomposition is used to derive graphs from unit-cells, and from the graphs generate training-pairs. As they show in the paper:
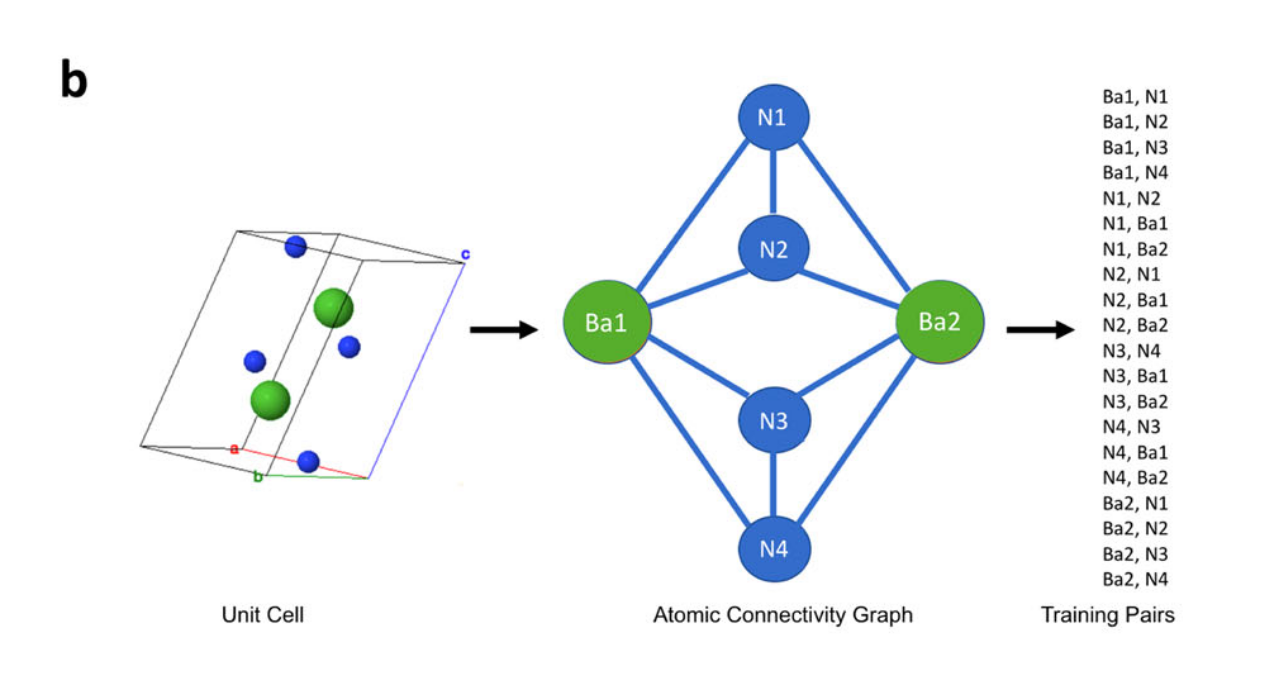
Image from Original Paper under CC-BY-SA 4.0
Finally, each pair X-Y is used to train a shallow network to predict the target (Y) from the reference (X).
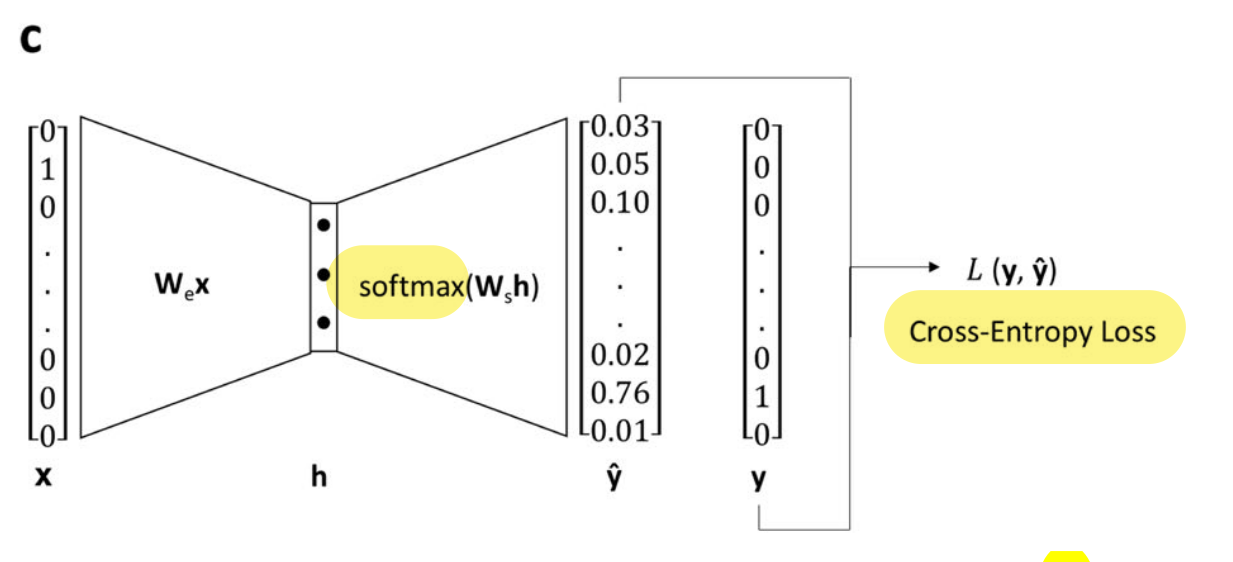
Image from Original Paper (slightly modified) under CC-BY-SA 4.0
- The resulting representation is dense and structured/semantic. This can be shown using dimensionality reduction techniques (PCA, t-SNE,..).
- The architecture is described as:
(...) single hidden layer with linear activation, whose size depended on the desired dimensionality of the learned embeddings, and an output layer with 86 neurons (one for each of the utilized atom types) with softmax activation. (...) minimizing the cross-entropy loss between the predicted context atom probabilities and the one-hot vector representing the context atom, given the one-vector representing the target atom as input.
Representations of Compounds (Pooling)
The analogy to NLP is that words are like atoms, and sentences are like compounds. Hence, distributed representations of atoms can be combined (pooled) into a vector representing a compound.
Vector-pooling options are:
- sum: where is the stoichiometry (can be fractional),
- mean: , i.e. divided by total number of atoms (can be fractional too).
- max: , reduces material matrix to vector. Selects max value of each column, each row being an atom in the compound.
The resulting compound representation is then used for training a feed-forward NN on different tasks. Also benchmarked using MatBench.
The pooling can also be done with hot-encoded vectors for atoms. This is done in ElemNet (mean pooling), and in Bag-of-atoms (sum pooling). The advantage: no training required, the disadvantage: the result is a sparse vector, and can be less accurate.
Results
They run two groups of tests:
- Embeddings' quality through elpasolite task. Where the atom vectors are concatenated into a compound vector (no pooling). The vectors train a network for property prediction. SkipAtom performs best here.
- Embeddings quality and pooling methods, through 9 prediction tasks. The results are:
- Pooling: sum and mean-pooling outperform max-pooling,
- Kind: Mat2Vec does best, and second SkipAtom,
- Bag-of-Atoms (sum pool of hot enc) does best in one task.
They conclude that these methods are most useful when no structural info is available.
However, there isn't a simple answer to which representation is best, it depends in the task. This is discussed in more detailed in Results.