Methods II
Visual Explainability Methods
-
Saliency Maps: visually show which features are most important in a particular prediction. They can be generated for 1D, 2D and ND inputs. For example, here is for radiology:
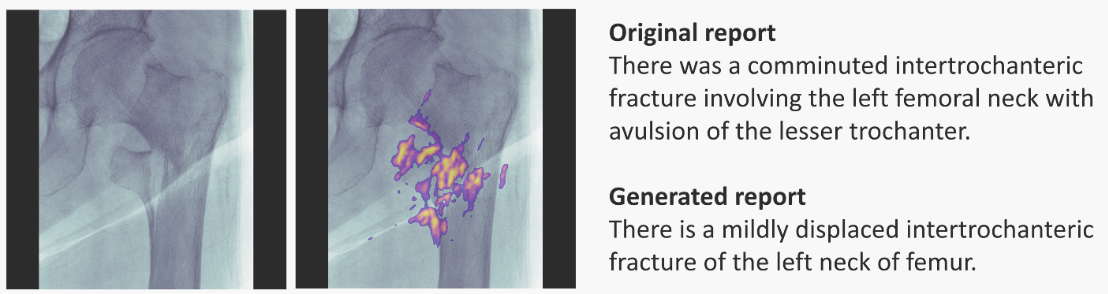
Left-most: input image; next: input + saliency map; right-most: doctor's annotation (top) and RNN-model generated annotation (bottom). Image taken from paper.
-
Variations: Individual Conditional Expectation, Partial Dependence Plots, can help visualise decision boundaries; they only vary 1 or 2 variables. Quotes below are snippets from original:
-
[ICE] operates on instance level, depicting the model's decision boundary as a function of a single feature, with the rest of them staying fixed.
-
(...) employ [ICE] plots to inspect the model's behaviour for a specific instance, where everything except salary is held constant, fixed to their observed values, while salary is free to attain different values.
- PDPs are a similar idea, but the remaining features are average values over the dataset points, rather than particular values of an instance.
-
-
Validity Interval Analysis: another technique fitting the NN behaviour to try to extract explanations.
Feature Relevance
- SHAP (possibly also LIME),
- Influence Functions.
Simplification
- LIME (possibly also SHAP). Explained in previous post,
- Anchors: the authors of LIME also proposed this nice method described by Principles and practice of explainability in ML:
-
A similar technique, called anchors, can be found in (Ribeiro et al., 2018). Here the objective is again to approximate a model locally, but this time not by using a linear model. Instead, easy to understand "if-then" rules that anchor the model's decision are employed. The rules aim at capturing the essential features, omitting the rest, so it results in more sparse explanations.
-
(...) decides to use anchors in order to achieve just that, generate easy-to-understand "if-then" rules that approximate the opaque model's behaviour in a local area (Figure 9). The resulting rules would now look something like "if salary is greater than 20 k£ and there are no missed payment, then the loan is approved.
-
Other methods
- Dimensionality Reduction: Principal Component Analysis, t-SNE, Dimensionality Reduction, Independent Component Analysis, Non-negative Matrix Factorisation.
- Counterfactuals: We replace the problem by a hypothetical opposite:
- A was the cause of B if, in an imaginary situation, A not happening implies B not happening.
- Change the instance slightly, but such that the model classifies the new instance in a different category.
-
(...) the applicant had missed one payment that led to this outcome, and that had he/she missed none the application would had been accepted
- Contrastive: Is about comparing carefully selected instances: Why P rather than Q?
-
In such cases, people expect to observe a particular event, but then observe another, with the observed event being the fact and the expected event being the foil.
- It's a good "question generator". What do you expect if X is done, rather than Y?
-
Explanation-producing Architectures
Architectures designed to make explaining part of their operation easier.
-
Using Explicit Attention: An attention layer/mask learns how parts of an input embedding pay attention to other parts. The layer is somewhat interpretable. In chemistry, it could learn which atoms connect (or pay attention to) other atoms.
-
Dissentangled Representations:
Disentangled representations have individual dimensions that describe meaningful and independent factors of variation.
—Explaining Explainability (2018). Examples of architectures are -VAE, INFOGan, capsule networks.